基于 k8s Job 进行模型微调
利用 Kubernetes (K8S) 原生 Job 负载实现离线执行模型微调任务,可以在提交任务后关闭容器实例,任务将自动在 GPU 工作空间中异步执行,并在完成后自动释放资源,确保计算资源的高效利用。
首先需要准备工作空间,并用kubectl连接成功。 具体步骤可以参考这里。(使用的分区为:华北二区)
以工作空间tenant-61616664-emei为例,安装kubectl后,配置myconf-eb-kubeconfig输出如下
bash
% kubectl --kubeconfig myconf-eb-kubeconfig get namespace
default Active 62d
# copy配置文件到默认路径
% cp myconf-eb-kubeconfig ~/.kube/config
# 执行命令,无需指定配置文件
% kubectl get namespace
NAME STATUS AGE
default Active 62d训练脚本设置
由于 Job 容器在任务结束后会被销毁,因此训练所用的脚本、以及生成的模型权重等文件必须保存在共享存储中。这样即使关闭容器实例,共享存储中的内容也不会消失。
准备持久化存储
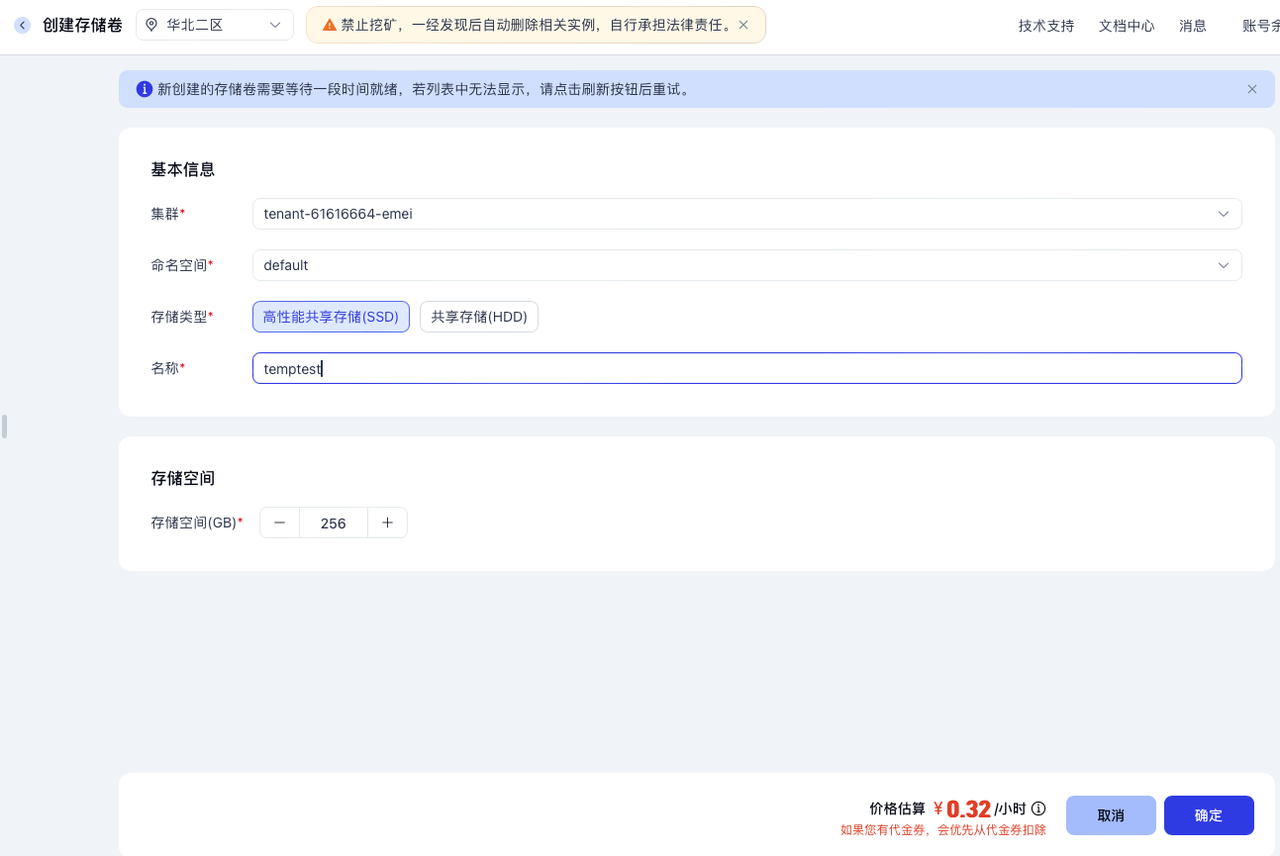
在英博云的控制台:存储 -> 共享存储卷 -> 创建存储卷,为tenant-61616664-emei工作空间建立一个存储卷,命名为temptest,如下所示:
开启一个容器实例并挂载共享存储
为了放置训练脚本,我们需要暂时开启一台容器实例。
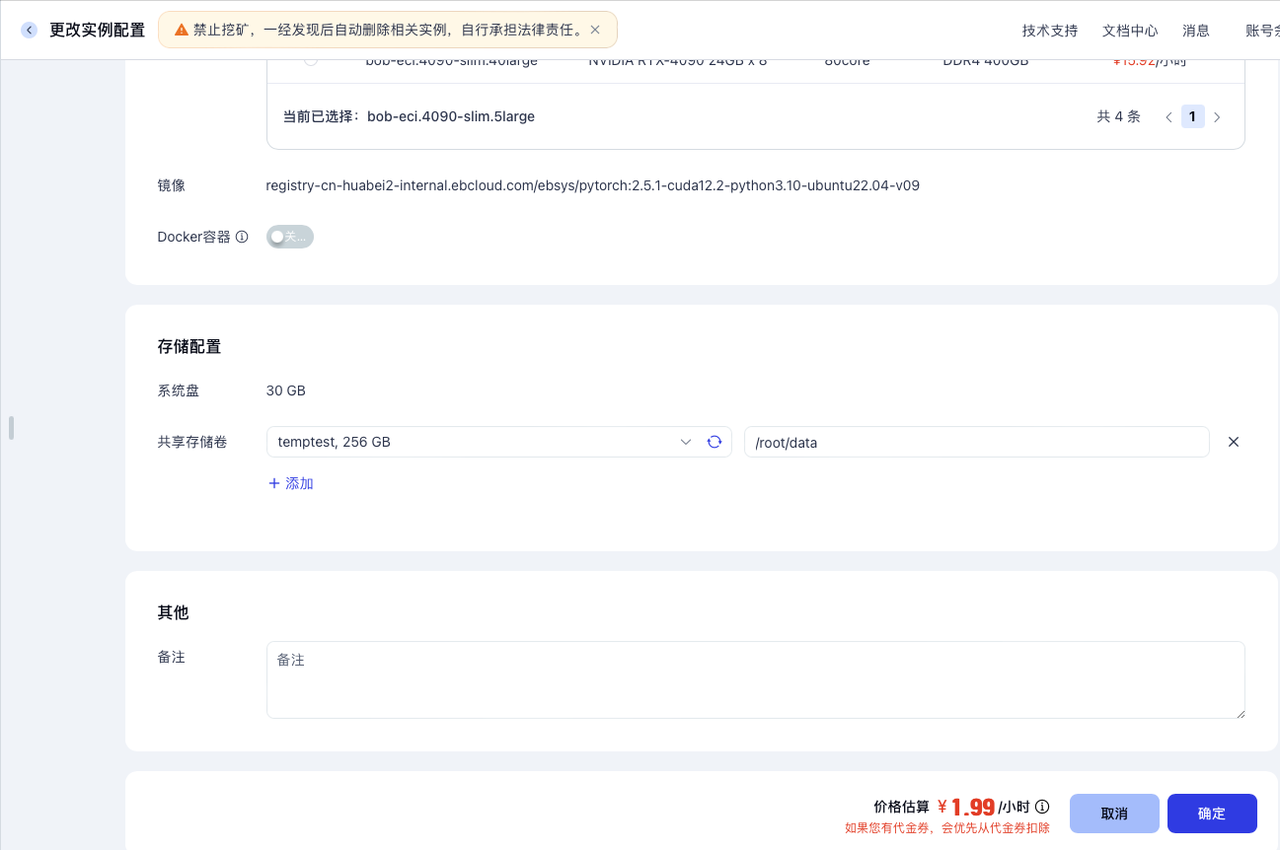
在容器实例列表页面,选择一个容器实例,点击更多 -> 更改实例配置,在接下来的页面中的存储配置部分为容器实例挂载存储卷,选择建好的共享存储卷temptest, 256 GB,并输入挂载路径,这里输入/root/data ,点击确定
设置存储路径
返回容器实例列表页面,开启挂载共享存储卷的容器实例,点击此容器实例的JupyterLab链接,进入指定的共享存储卷路径(示例为/root/data),在左侧空白栏右键创建example-train文件夹和train_model.py,也可以在JupyterLab的Launcher页,点击Terminal进入终端,使用指令创建。


准备模型
英博云上已经预置了Huggingface最新的常用开源模型和代码。
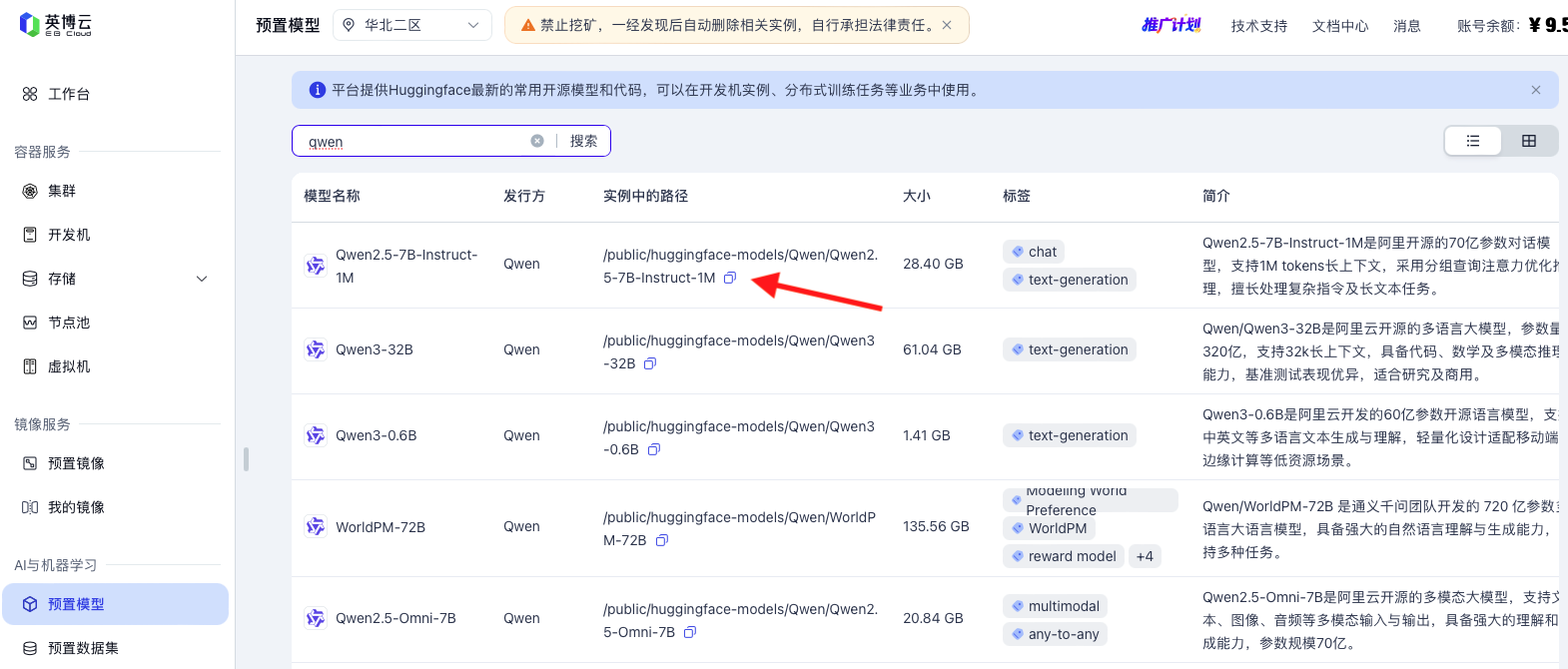
在英博云的控制台AI与机器学习点击预置模型,搜索qwen,选择Qwen2.5-7B-Instruct-1M行,点击实例中的路径列末尾的复制按钮,此时模型路径 /public/huggingface-models/Qwen/Qwen2.5-7B-Instruct-1M已经复制到了剪贴板中。
注意
- 不同的工作空间分区提供的模型略有不同,请按需选择。
华北二区是4090专属分区,且工作空间tenant-61616664-emei的GPU配额为2卡,因此示例使用Qwen2.5-7B-Instruct-1M模型进行指令微调(SFT)。- 针对不同的任务,如需提高GPU配额,请点击英博云的控制台:
工作空间 -> 选择要调整的工作空间 -> 更多 -> 调整配额 -> 工作空间配额上限申请,填写适合的配额要求及理由,等待审核通过。
准备训练数据
使用预置数据集
英博云上提供Huggingface最新的常用开源数据集和部分垂直领域数据集.
在英博云的控制台AI与机器学习点击预置数据集,查看英博云上是否有您需要的数据集。
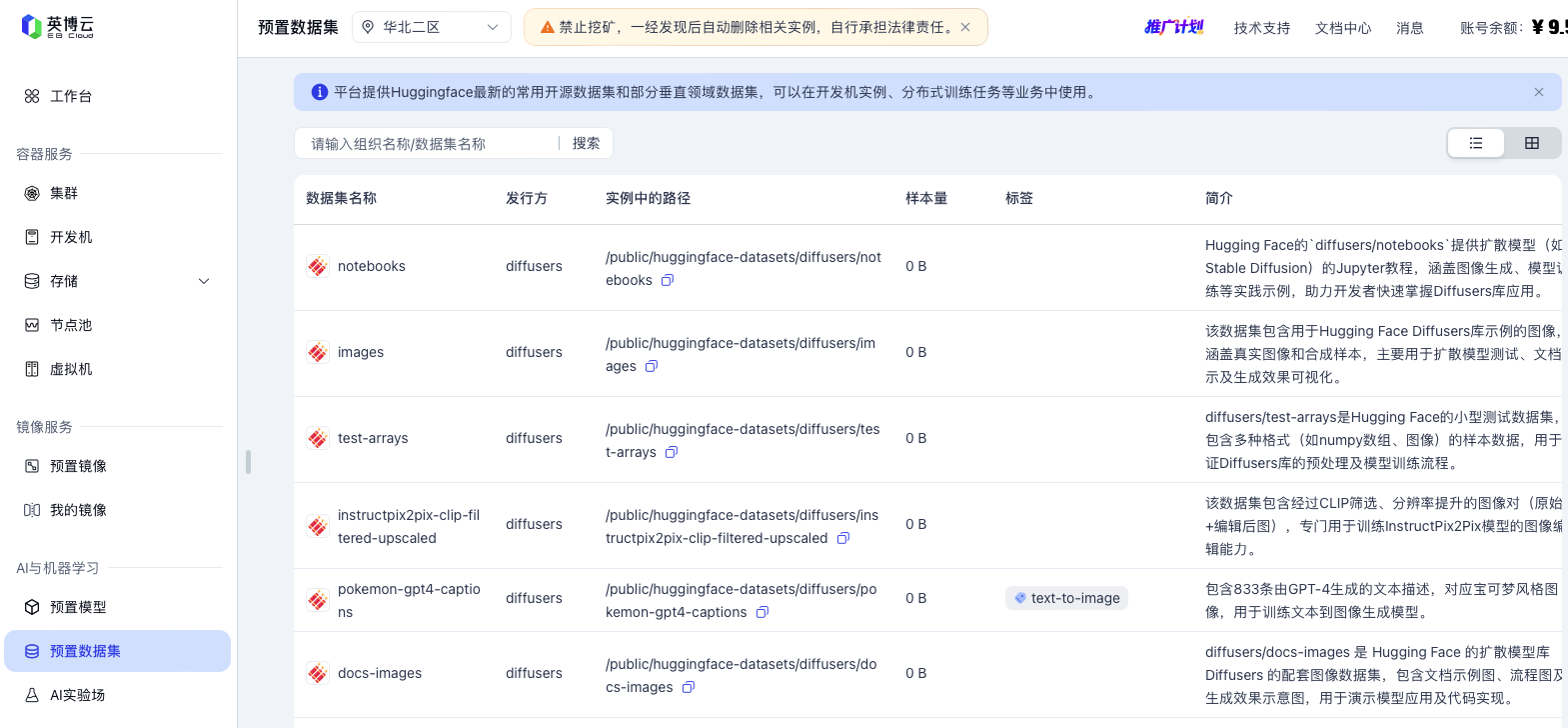
注意
- 不同的工作空间分区提供的数据集略有不同,请按需选择。
上传训练数据集
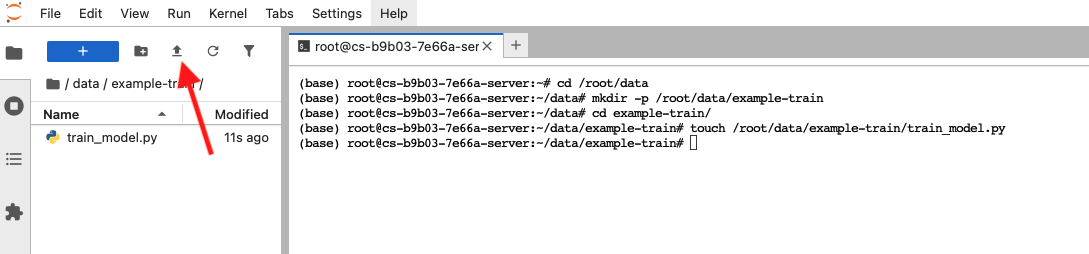
如果预置数据集中没有需要的数据,返回容器实例页面,点击JupyterLab左侧控制栏上方蓝色按钮右侧第二个箭头按钮,选择本地文件上传。这里示例上传经典数据集mother_v1.json。
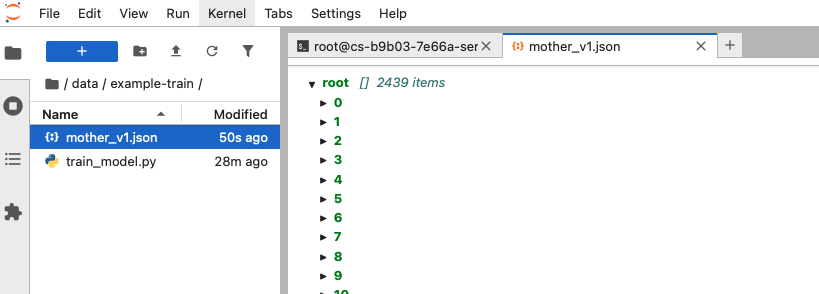
上传后的结果如下
准备脚本
在train_model.py中写入以下内容
python
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from peft import LoraConfig, prepare_model_for_kbit_training
from trl import SFTTrainer
os.environ["NCCL_P2P_DISABLE"] = "1"
os.environ["NCCL_IB_DISABLE"] = "1"
# --- 1. 配置参数 ---
model_name = "/public/huggingface-models/Qwen/Qwen2.5-7B-Instruct-1M"
dataset_path = "/root/data/example-train/mother_v1.json"
output_dir = "/root/data/example-train/qwen2.5-7b-instruct-lora"
# --- 2. 加载 Tokenizer ---
print("--- 正在加载 Tokenizer... ---")
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
print("--- Tokenizer 加载完成 ---")
# --- 3. 数据处理函数 (保留修复后的版本) ---
def transform_to_chat_format(example):
messages = []
conversations = example.get('conversation', [])
if not isinstance(conversations, list):
return {"text": ""}
for turn in conversations:
system_prompt = turn.get("system")
user_input = turn.get("input")
assistant_output = turn.get("output")
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
if user_input:
messages.append({"role": "user", "content": user_input})
if assistant_output:
messages.append({"role": "assistant", "content": assistant_output})
if not messages:
return {"text": ""}
try:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
return {"text": text}
except Exception as e:
return {"text": ""}
print("--- 正在加载和处理数据集... ---")
dataset = load_dataset("json", data_files=dataset_path, split="train")
processed_dataset = dataset.map(transform_to_chat_format)
# 过滤无效数据
processed_dataset = processed_dataset.filter(lambda x: x["text"] != "")
print(f"--- 数据集处理完成,有效数据: {len(processed_dataset)} 条 ---")
# --- 4. 加载 4-bit 量化模型 (QLoRA) ---
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
print("--- 正在加载模型... ---")
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto", # 单卡直接用 auto 即可
trust_remote_code=True
)
# 开启梯度检查点 (大幅节省显存)
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
model.config.use_cache = False
print("--- 模型加载完成 ---")
# --- 5. LoRA 配置 ---
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)
# --- 6. 训练参数 ---
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=3,
# 单卡 4090 显存很大,可以适当调大 batch size
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # 等效 batch size = 16
optim="paged_adamw_32bit",
save_steps=100,
save_total_limit=2,
logging_steps=10,
learning_rate=2e-4,
fp16=False,
bf16=True, # 4090 必须开 BF16
max_grad_norm=0.3,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="cosine",
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=processed_dataset,
dataset_text_field="text",
peft_config=peft_config,
max_seq_length=4096,
tokenizer=tokenizer,
args=training_arguments,
)
print("--- 开始训练 ---")
trainer.train()
final_output_dir = os.path.join(output_dir, "final_checkpoint")
trainer.save_model(final_output_dir)
tokenizer.save_pretrained(final_output_dir)
print(f"--- 训练完成!LoRA 适配器已保存至: {final_output_dir} ---")关闭容器实例
此时所有准备都已经做好,后续步骤无需容器实例参与,为了节省费用,可以关闭容器实例。
返回容器实例列表页面,选择容器实例,点击更多 -> 关机。
部署 Job 服务
Job 配置文件定义了“用什么镜像”、“跑什么代码”以及“何时删除”。
获取推理需要的镜像
英博云上提供了常用的基础容器镜像,集成分布式计算框架等服务。
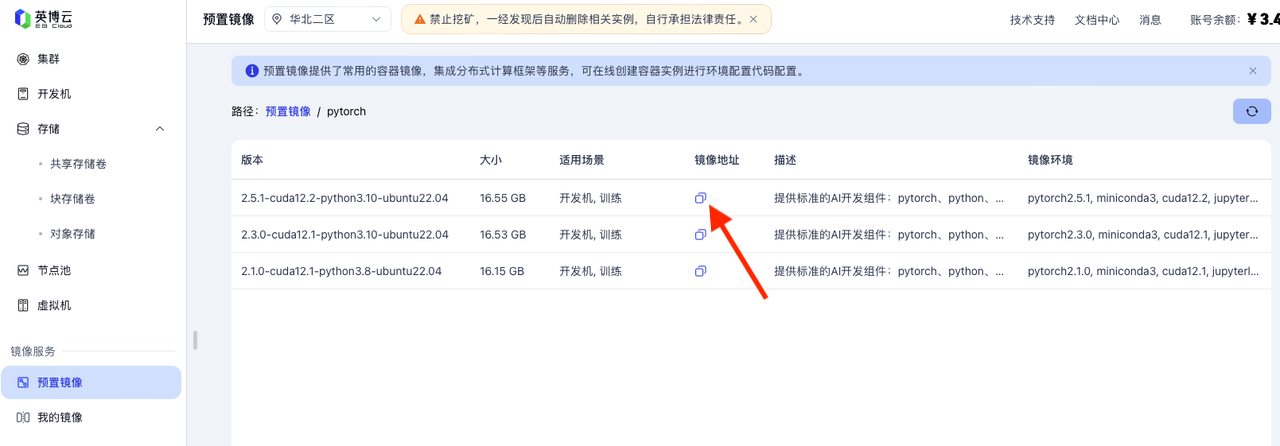
在英博云的控制台镜像服务点击预置镜像,点击预置镜像列表中的镜像仓库名称pytorch,选择适合的版本复制镜像地址,这里选择第一个。
准备 Job yaml文件
在本地或管理终端创建一个名为 job.yaml 文件,并写入以下内容:
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: qwen-finetune-job
spec:
template:
metadata:
annotations:
# 指定资源规格
cloud.ebtech.com/resource-flavor: "bob-eci.4090-slim.5large"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values:
- RTX_4090
containers:
- name: trainer
# 使用复制的镜像地址
image: registry-cn-huabei2-internal.ebcloud.com/ebsys/pytorch:2.5.1-cuda12.2-python3.10-ubuntu22.04-v09
command: ["/bin/bash", "-c"]
args:
- |
echo "1. Installing dependencies..."
pip install transformers==4.41.2 datasets==2.19.2 peft==0.11.1 accelerate==0.30.1 bitsandbytes==0.43.1 trl==0.8.6 -i https://pypi.tuna.tsinghua.edu.cn/simple
echo "2. Starting Qwen training..."
python3 /root/data/example-train/train_model.py
resources:
limits:
nvidia.com/gpu: 2 # 这里上限由工作空间配额决定
requests:
nvidia.com/gpu: 2
volumeMounts:
- name: dshm-volume
mountPath: /dev/shm
- name: data-volume
mountPath: /root/data # 挂载路径需与脚本内部一致
- name: public-volume
mountPath: /public # 挂载宿主机的 /public 目录
readOnly: true
volumes:
- name: dshm-volume
emptyDir:
medium: Memory
sizeLimit: 32Gi
- name: data-volume
persistentVolumeClaim:
claimName: temptest # 这里填写创建的存储卷名称
- name: public-volume # --- hostPath 方式连接预置模型 ---
hostPath:
path: /public
type: Directory
restartPolicy: Never注意
执行部署命令
shell
# 提交任务
kubectl apply -f job.yaml此时,工作空间会自动调度 GPU 资源并开始训练,而您的容器实例保持关机状态(零开机费用)。
查看进度
shell
# 查看任务是否已成功创建
kubectl get jobs
kubectl get pobs
# 实时查看训练日志 (找到 pod 名称后替换)
kubectl logs -f qwen-finetune-job-xxxxx运行大约四十分钟后完成
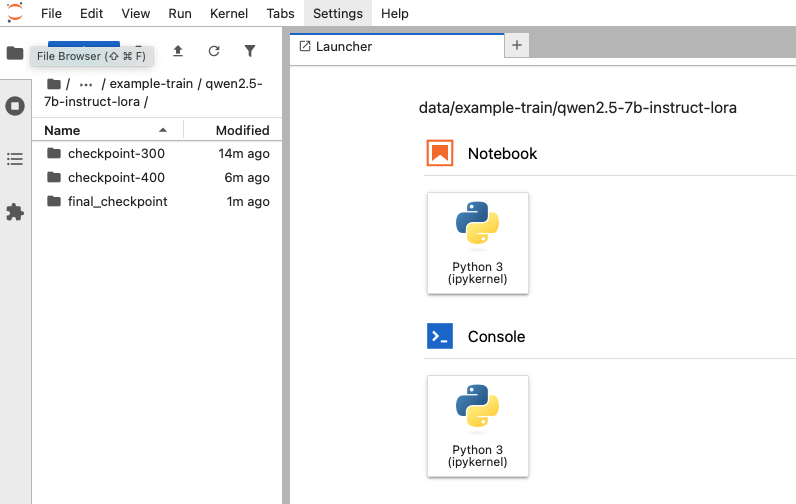
获取模型产出
当日志显示训练结束后,Job状态会变为Completed。再次执行logs -f qwen-finetune-job-xxxxx,您可以看到完整的训练输出。
重新启动容器实例,进入/root/data/example-train目录,可以看到生成的qwen2.5-7b-instruct-lora文件夹,进入目录即可查看保存的结果。