

Local Storage 本地存储
基本介绍
local storage 在 pod 所在的物理机节点分配一块 ephemeral 存储空间。 该空间为临时性存储,Pod 重建、删除或调度时数据会丢失。适用场景为业务需要大容量本地存储,且无需持久化保存数据。
注意:
- 专属节点、预约专属节点中的工作负载,开启本地存储不会再额外收取费用。
不同规格支持的 local storage 容量上限
目前仅A800,H800,H100支持 local storage。
H800支持的 local storage 上限
| 规格名称 | 容量上限 |
|---|---|
| bob-eci.h800.5xlarge | 768 GB |
| bob-eci.h800.10xlarge | 1536 GB |
| bob-eci.h800.20xlarge | 3072 GB |
| bob-eci.h800.40xlarge | 6144 GB |
A800支持的 local storage 上限
| 规格名称 | 容量上限 |
|---|---|
| bob-eci.a800.5large | 768 GB |
| bob-eci.a800.10large | 1536 GB |
| bob-eci.a800.20large | 3072 GB |
| bob-eci.a800.40large | 6144 GB |
| bob-eci.a800.5xlarge | 768 GB |
| bob-eci.a800.10xlarge | 1536 GB |
| bob-eci.a800.20xlarge | 3072 GB |
| bob-eci.a800.40xlarge | 6144 GB |
H100支持的 local storage 上限
| 规格名称 | 容量上限 |
|---|---|
| bob-eci.h100.5xlarge | 768 GB |
| bob-eci.h100.10xlarge | 1536 GB |
| bob-eci.h100.20xlarge | 3072 GB |
| bob-eci.h100.40xlarge | 6144 GB |
基于容器实例使用本地存储
具体示例如下:
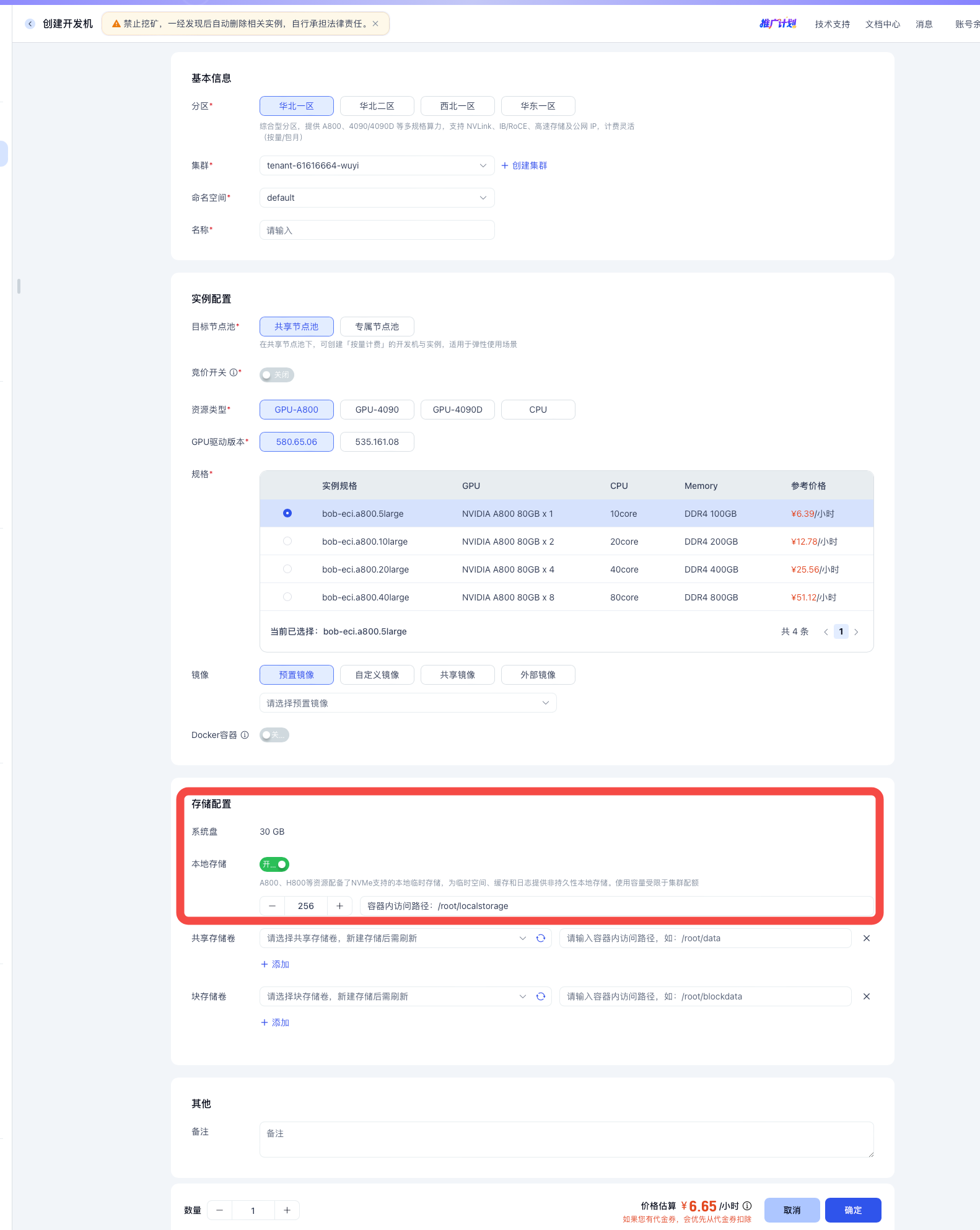
基于 k8s 工作负责使用本地存储
Storage Class
ephemeral-els-premium
注意:
- 不可以直接用这个sc创建pvc,需要与pod一同使用。
- 参考下面的示例。
Deployment 使用本地存储 yaml 示例
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test1
namespace: default
labels:
app: test1
spec:
replicas: 1
selector:
matchLabels:
app: test1
template:
metadata:
labels:
app: test1
spec:
schedulerName: volcano
terminationGracePeriodSeconds: 1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values: ["A800_NVLINK_80GB"]
containers:
- name: server
image: registry-cn-huabei1-internal.ebcloud.com/ebsys/pytorch:2.7.0-cuda12.9-python3.12-ubuntu24.04-v01
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- |
# 捕获 SIGTERM 信号并立即退出
trap 'echo "Received SIGTERM, exiting..."; exit 0' SIGTERM
# 使用一个简单的循环,而不是 sleep infinity
# 这样可以更快地响应信号
while true; do
sleep 1
done
resources:
limits:
cpu: "10"
memory: 100Gi
nvidia.com/gpu: "1"
securityContext:
capabilities:
add: ["IPC_LOCK"]
volumeMounts:
- mountPath: /mnt/tmp-test1
name: tmp-test1
volumes:
- name: tmp-test1
ephemeral:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 500Gi
storageClassName: ephemeral-els-premium
volumeMode: FilesystemStatefulSet 使用本地存储 yaml 示例
yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: test2
namespace: default
labels:
app: test2
spec:
replicas: 1
serviceName: test2
selector:
matchLabels:
app: test2
template:
metadata:
labels:
app: test2
spec:
schedulerName: volcano
terminationGracePeriodSeconds: 1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values: ["A800_NVLINK_80GB"]
containers:
- name: server
image: registry-cn-huabei1-internal.ebcloud.com/ebsys/pytorch:2.7.0-cuda12.9-python3.12-ubuntu24.04-v01
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- |
# 捕获 SIGTERM 信号并立即退出
trap 'echo "Received SIGTERM, exiting..."; exit 0' SIGTERM
# 使用一个简单的循环,而不是 sleep infinity
# 这样可以更快地响应信号
while true; do
sleep 1
done
resources:
limits:
cpu: "10"
memory: 100Gi
nvidia.com/gpu: "1"
securityContext:
capabilities:
add: ["IPC_LOCK"]
volumeMounts:
- mountPath: /mnt/tmp-test1
name: tmp-test1
volumes:
- name: tmp-test1
ephemeral:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 500Gi
storageClassName: ephemeral-els-premium
volumeMode: FilesystemPod 使用本地存储 yaml 示例
yaml
apiVersion: v1
kind: Pod
metadata:
name: test3
namespace: default
labels:
app: test3
spec:
schedulerName: volcano
terminationGracePeriodSeconds: 1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values: ["A800_NVLINK_80GB"]
containers:
- name: server
image: registry-cn-huabei1-internal.ebcloud.com/ebsys/pytorch:2.7.0-cuda12.9-python3.12-ubuntu24.04-v01
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- |
# 捕获 SIGTERM 信号并立即退出
trap 'echo "Received SIGTERM, exiting..."; exit 0' SIGTERM
# 使用一个简单的循环,而不是 sleep infinity
# 这样可以更快地响应信号
while true; do
sleep 1
done
resources:
limits:
cpu: "10"
memory: 100Gi
nvidia.com/gpu: "1"
securityContext:
capabilities:
add: ["IPC_LOCK"]
volumeMounts:
- mountPath: /mnt/tmp-test1
name: tmp-test1
volumes:
- name: tmp-test1
ephemeral:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 500Gi
storageClassName: ephemeral-els-premium
volumeMode: Filesystem