'%3e%3cpath%20d='M14.584%204.27734L21.9274%208.55391V23.9564L14.584%2019.6798V4.27734Z'%20fill='%2368E053'/%3e%3cpath%20d='M7.34375%2024.2458L14.6871%2028.5224L21.9284%2023.9563L14.5849%2019.6797L7.34375%2024.2458Z'%20fill='%2359C239'/%3e%3cpath%20d='M0%204.58398L7.34342%208.86055V24.263L0%2019.9864V4.58398Z'%20fill='%232E4EF5'/%3e%3cpath%20d='M0%204.58325L7.34342%208.85981L14.5846%204.27657L7.2412%200L0%204.58325Z'%20fill='%23306FF5'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M32.134%202.5H34.073V3.95418H38.7817V2.5H40.6513V3.95418H44.1829V5.26987H40.6513V7.00103H38.7817V5.26987H34.073V7.00103H32.134V5.26987H28.5332V3.95418H32.134V2.5ZM37.3981%206.86328H35.5285V7.97123H30.6119V11.7798H28.6038V13.3724H35.5285V13.8572L28.5%2019.3969L31.0967%2019.5008L36.4287%2015.3114L42.0031%2019.3969H44.4266L37.3981%2013.8572V13.3724H44.4613V11.7798H42.4532V7.97123H37.3981V6.86328ZM32.5509%209.28693V11.7798H35.5285V9.28693H32.5509ZM37.3981%2011.7798V9.28693H40.5834V11.7798H37.3981ZM55.7496%202.5H57.6885V4.30041H61.9125V5.26987H57.6885V5.89309H61.6355V11.5092C61.6355%2011.6241%2061.5422%2011.7172%2061.4272%2011.7169L58.5195%2011.7097V10.7403H59.7659V10.3249H57.6885V12.3331H55.7496V10.3249H54.1569V11.6405H52.218V5.89309H55.7496V5.26987H51.6641V4.30041H55.7496V2.5ZM54.1569%206.86253V7.555H55.7496V6.86253H54.1569ZM57.6885%206.86253V7.555H59.7659V6.86253H57.6885ZM54.1569%208.52446V9.35538H55.7496V8.52446H54.1569ZM57.6885%208.52446V9.35538H59.7659V8.52446H57.6885ZM50.4867%202.70703H48.617V6.10012H46.9551V7.5543H48.617V19.1878H50.4867V7.5543H51.8716V6.10012H50.4867V2.70703ZM60.874%2012.2637H59.0043V12.6099H51.8027V14.1333H59.0043V18.0111H56.3038L56.65%2019.1884H60.874V14.1333H62.2589V12.6099H60.874V12.2637ZM56.9265%2014.8945H53.6719L54.0181%2016.3487H57.3419L56.9265%2014.8945ZM61.1485%202.70703H58.8633L59.2095%203.81498H61.4947L61.1485%202.70703ZM66.6719%203.2168H79.0052V4.62452H66.6719V3.2168ZM65.6543%208.70703H80.0257V10.1148H70.8852L68.6858%2016.3148V17.2186L76.5439%2017.1485L75.6054%2014.6615H77.6084L79.2052%2018.8789H77.9236H77.2022H66.8789V15.8805L68.9924%2010.1148H65.6543V8.70703Z'%20fill='%23020617'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M35.1498%2021.7207H29.8315L29.0001%2022.6114L29%2025.7296L29.8313%2026.6204L35.1498%2026.6205V25.8118H30.1331L29.8088%2025.4556V22.8855L30.133%2022.5294H35.1498V21.7207ZM44.2616%2021.721L38.4319%2021.7208V26.6206L44.2616%2026.6207L45.0928%2025.7299V22.6117L44.2616%2021.721ZM39.2407%2025.8119V22.5296H43.9598L44.2841%2022.8858V23.7095H40.0794V24.5182H44.2841V25.4557L43.9598%2025.8119H39.2407ZM35.1498%2023.7093H30.4205V24.5181H35.1498V23.7093ZM58.7072%2021.7246H53.294L53.1593%2021.8818C53.0539%2022.0048%2052.9711%2022.1017%2052.8887%2022.1981L52.8873%2022.1998L52.8859%2022.2014C52.8035%2022.2979%2052.7211%2022.3943%2052.6161%2022.5169L52.5078%2022.6433V25.693L52.6161%2025.8194C52.7216%2025.9425%2052.8046%2026.0396%2052.8873%2026.1365L52.8877%2026.1369C52.9704%2026.2338%2053.0534%2026.3309%2053.1593%2026.4545L53.294%2026.6117H58.7989V25.7117H53.7079L53.5713%2025.5517L53.4075%2025.3602V22.9761L53.5713%2022.7845L53.7079%2022.6246H58.7072V21.7246ZM67.2254%2022.8677H63.6288L63.0125%2023.4842V26.0093L63.3319%2026.3288L63.4017%2026.3985L63.6288%2026.6257H67.2254L67.659%2026.192L67.8417%2026.0093V23.4842L67.2254%2022.8677ZM63.9123%2023.857L64.0015%2023.7677H66.8528L66.942%2023.857V25.6365L66.8528%2025.7257H64.0015L63.9123%2025.6365V23.857ZM68.8604%2023.0002H69.7601V25.5378C69.8143%2025.6014%2069.8624%2025.6573%2069.9159%2025.7187H72.7353C72.7889%2025.6559%2072.8387%2025.5983%2072.8957%2025.5331V23.0002H73.7954V25.8735L73.6825%2026.0011C73.523%2026.1815%2073.4406%2026.2777%2073.2868%2026.4594L73.1521%2026.6187H69.5097L69.3754%2026.4669C69.2104%2026.2803%2069.1235%2026.1789%2068.9668%2025.9937L68.8604%2025.8678V23.0002ZM60.6988%2021.8289V26.5005H61.5985V21.8289H60.6988ZM78.6036%2024.5813V23.7679H75.6552L75.566%2023.8571V25.6366L75.6552%2025.7258H78.5041L78.6039%2025.6275V24.5813H78.6036ZM79.5036%2023.6566V21.7939H78.6036V22.8679H75.2826L74.6663%2023.4843V26.0094L75.2826%2026.6258H78.8058V26.4814L78.9109%2026.5883L79.5039%2026.0044V23.6566H79.5036Z'%20fill='%23020617'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_6697_31479'%3e%3crect%20width='82'%20height='28.5217'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
基于k8s job执行推理
利用 Kubernetes (K8S) 原生 Job 负载实现离线执行推理任务,可以在提交任务后关闭开发机,任务将自动在 GPU 集群中异步执行,并在完成后自动释放资源,确保计算资源的高效利用。
首先需要准备集群,并用kubectl连接成功。 具体步骤可以参考这里。(使用的分区为:华北二区)
准备推理脚本
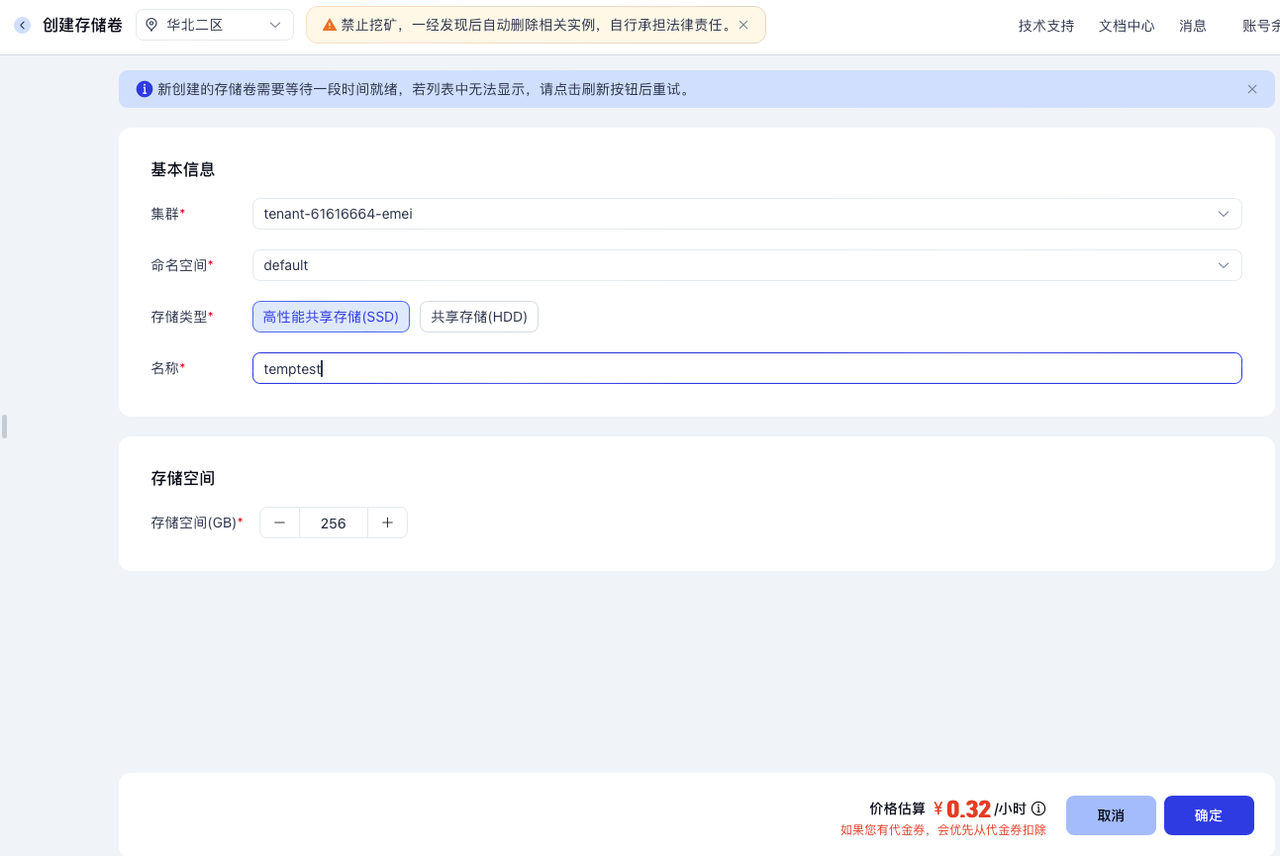
准备一个共享存储
在英博云的控制台:存储 -> 共享存储卷 -> 创建存储卷,建立一个存储卷,命名为temptest,如下所示:
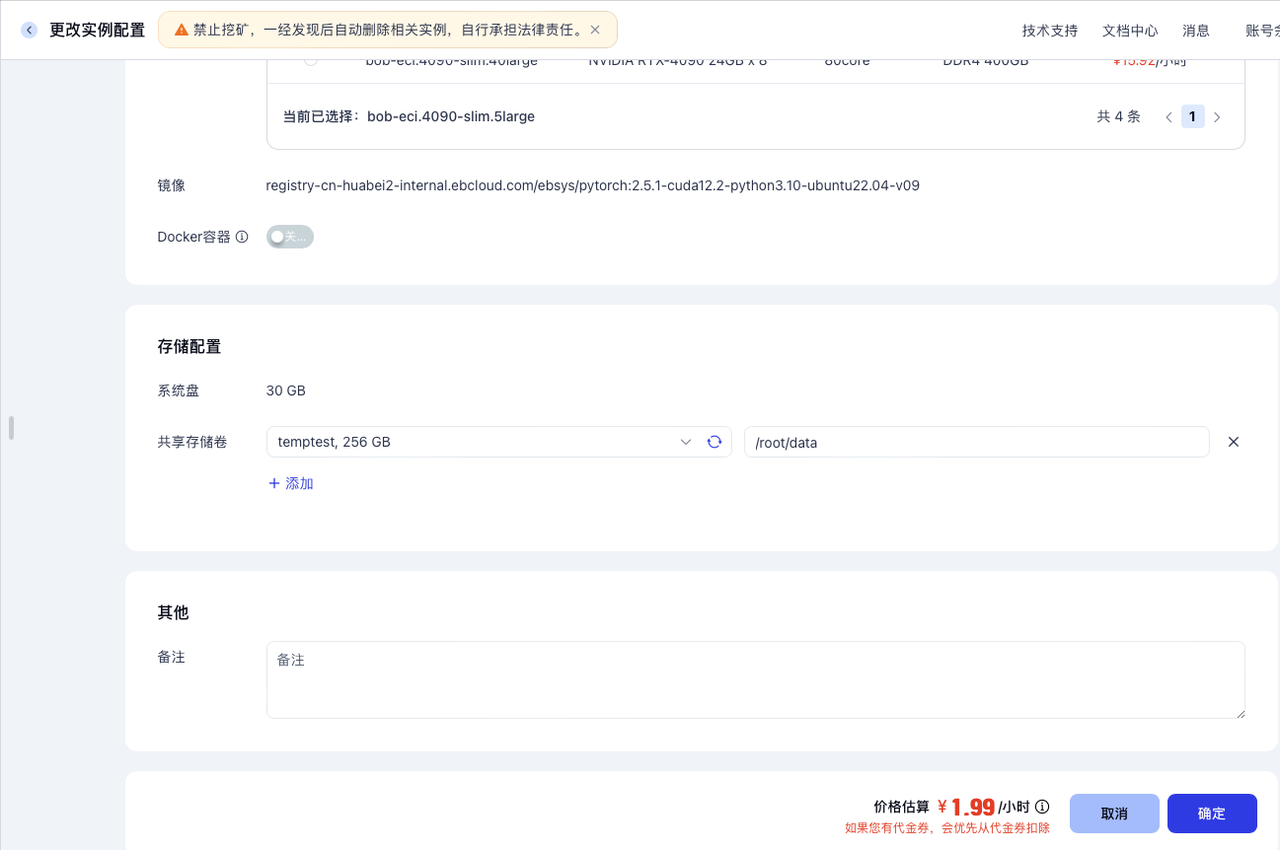
开启一个开发机并挂载共享存储
在开发机列表页面,选择一个开发机,点击更多 -> 更改实例配置,在接下来的页面中的存储配置部分为开发机挂载存储卷,选择建好的共享存储卷temptest, 256 GB,并输入挂载路径,这里输入/root/data ,点击确定
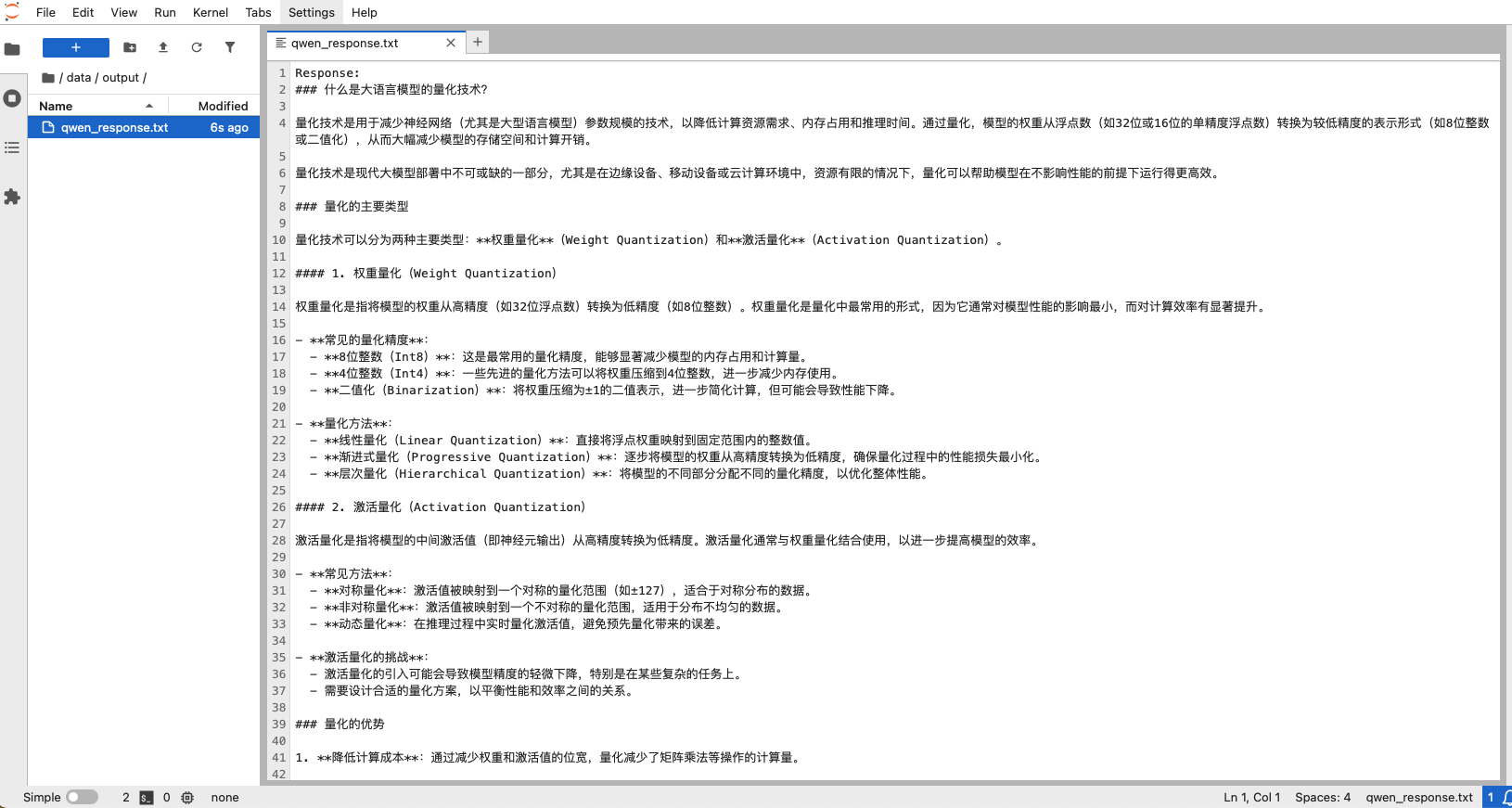
编辑推理脚本
返回开发机列表页面,开启挂载共享存储卷的开发机,点击此开发机的JupyterLab链接,进入指定的共享存储卷路径(示例为/root/data),在左侧空白栏右键创建inference.py文件和output文件夹,也可以在JupyterLab的Launcher页,点击Terminal进入终端,使用指令创建。

在inference.py中写入以下内容:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def run_inference():
model_path = "/public/huggingface-models/Qwen/Qwen2.5-7B-Instruct-1M"
print("正在加载分词器...")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
print("正在加载模型(使用 BF16 精度)...")
# 4090 支持 BF16,建议优先使用 BF16
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
prompt = "请详细解释一下什么是大语言模型的量化技术?"
messages = [
{"role": "system", "content": "你是一个严谨的 AI 助手。"},
{"role": "user", "content": prompt}
]
# 使用 Qwen 特有的 chat 模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
print("--- 开始生成 ---")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.7,
top_p=0.9
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
] # 过滤掉输入部分,只保留生成部分
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
output_file = "/root/data/output/qwen_response.txt"
with open(output_file, "w", encoding="utf-8") as f:
f.write(f"Response:\n{response}\n")
if __name__ == "__main__":
run_inference()
关闭开发机
此时所有准备都已经做好,可以关闭开发机。
返回开发机列表页面,选择开发机,点击更多 -> 关机。
部署 Job 服务
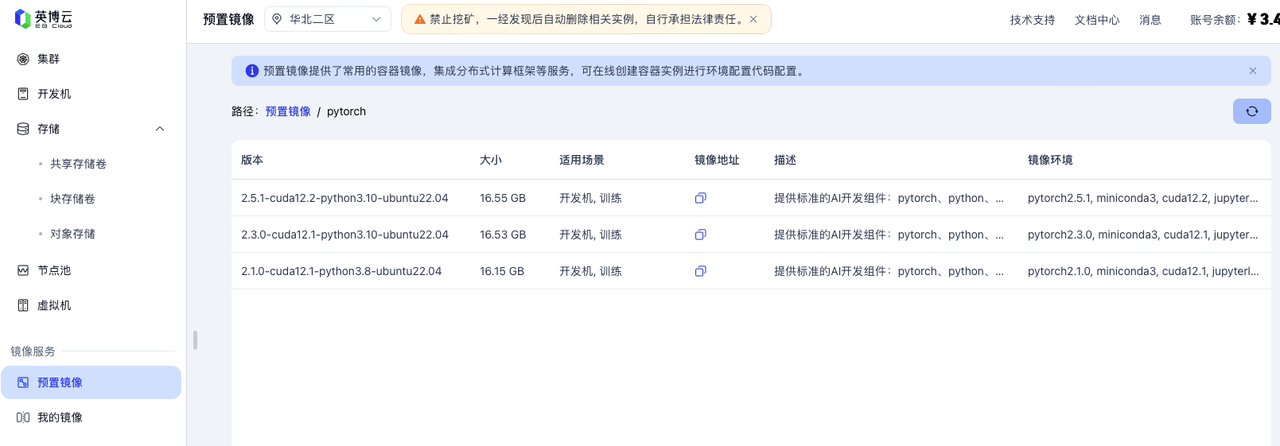
获取推理需要的镜像
在英博云控制台左侧边栏镜像服务中点击预置镜像,点击预置镜像列表中的镜像仓库名称pytorch,选择适合的版本复制镜像地址。
准备 Job yaml文件
Job 配置文件定义了资源需求、节点亲和性及自动清理策略。
准备如下的 job.yaml 文件:
apiVersion: batch/v1
kind: Job
metadata:
name: pytorch-official-job
spec:
ttlSecondsAfterFinished: 60 # 任务完成后60秒自动清理
template:
metadata:
annotations:
cloud.ebtech.com/resource-flavor: "bob-eci.4090-slim.5large"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values:
- RTX_4090
containers:
- name: worker
# 使用前面复制的镜像地址
image: registry-cn-huabei2-internal.ebcloud.com/ebsys/pytorch:2.5.1-cuda12.2-python3.10-ubuntu22.04-v09
command: ["/bin/bash", "-c"]
args:
- |
pip install accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
echo "Starting inference script..."
python3 /root/data/inference.py
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
volumeMounts:
- name: data-volume
mountPath: /root/data # 开发机共享存储卷路径
- name: public-volume
mountPath: /public # 挂载宿主机的 /public 目录
readOnly: true
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: temptest # 共享存储卷名称
- name: public-volume # --- hostPath 方式连接预置模型 ---
hostPath:
path: /public
type: Directory
restartPolicy: Never
执行部署命令
# 提交任务,之后直接关机
kubectl apply -f job.yaml
查看进度
# 查看任务是否已成功创建
kubectl get jobs
kubectl get pobs
获取模型产出
重新启动开发机,进入/root/data/output目录,查看qwen_response.txt的内容