'%3e%3cpath%20d='M14.584%204.27734L21.9274%208.55391V23.9564L14.584%2019.6798V4.27734Z'%20fill='%2368E053'/%3e%3cpath%20d='M7.34375%2024.2458L14.6871%2028.5224L21.9284%2023.9563L14.5849%2019.6797L7.34375%2024.2458Z'%20fill='%2359C239'/%3e%3cpath%20d='M0%204.58398L7.34342%208.86055V24.263L0%2019.9864V4.58398Z'%20fill='%232E4EF5'/%3e%3cpath%20d='M0%204.58325L7.34342%208.85981L14.5846%204.27657L7.2412%200L0%204.58325Z'%20fill='%23306FF5'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M32.134%202.5H34.073V3.95418H38.7817V2.5H40.6513V3.95418H44.1829V5.26987H40.6513V7.00103H38.7817V5.26987H34.073V7.00103H32.134V5.26987H28.5332V3.95418H32.134V2.5ZM37.3981%206.86328H35.5285V7.97123H30.6119V11.7798H28.6038V13.3724H35.5285V13.8572L28.5%2019.3969L31.0967%2019.5008L36.4287%2015.3114L42.0031%2019.3969H44.4266L37.3981%2013.8572V13.3724H44.4613V11.7798H42.4532V7.97123H37.3981V6.86328ZM32.5509%209.28693V11.7798H35.5285V9.28693H32.5509ZM37.3981%2011.7798V9.28693H40.5834V11.7798H37.3981ZM55.7496%202.5H57.6885V4.30041H61.9125V5.26987H57.6885V5.89309H61.6355V11.5092C61.6355%2011.6241%2061.5422%2011.7172%2061.4272%2011.7169L58.5195%2011.7097V10.7403H59.7659V10.3249H57.6885V12.3331H55.7496V10.3249H54.1569V11.6405H52.218V5.89309H55.7496V5.26987H51.6641V4.30041H55.7496V2.5ZM54.1569%206.86253V7.555H55.7496V6.86253H54.1569ZM57.6885%206.86253V7.555H59.7659V6.86253H57.6885ZM54.1569%208.52446V9.35538H55.7496V8.52446H54.1569ZM57.6885%208.52446V9.35538H59.7659V8.52446H57.6885ZM50.4867%202.70703H48.617V6.10012H46.9551V7.5543H48.617V19.1878H50.4867V7.5543H51.8716V6.10012H50.4867V2.70703ZM60.874%2012.2637H59.0043V12.6099H51.8027V14.1333H59.0043V18.0111H56.3038L56.65%2019.1884H60.874V14.1333H62.2589V12.6099H60.874V12.2637ZM56.9265%2014.8945H53.6719L54.0181%2016.3487H57.3419L56.9265%2014.8945ZM61.1485%202.70703H58.8633L59.2095%203.81498H61.4947L61.1485%202.70703ZM66.6719%203.2168H79.0052V4.62452H66.6719V3.2168ZM65.6543%208.70703H80.0257V10.1148H70.8852L68.6858%2016.3148V17.2186L76.5439%2017.1485L75.6054%2014.6615H77.6084L79.2052%2018.8789H77.9236H77.2022H66.8789V15.8805L68.9924%2010.1148H65.6543V8.70703Z'%20fill='%23020617'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M35.1498%2021.7207H29.8315L29.0001%2022.6114L29%2025.7296L29.8313%2026.6204L35.1498%2026.6205V25.8118H30.1331L29.8088%2025.4556V22.8855L30.133%2022.5294H35.1498V21.7207ZM44.2616%2021.721L38.4319%2021.7208V26.6206L44.2616%2026.6207L45.0928%2025.7299V22.6117L44.2616%2021.721ZM39.2407%2025.8119V22.5296H43.9598L44.2841%2022.8858V23.7095H40.0794V24.5182H44.2841V25.4557L43.9598%2025.8119H39.2407ZM35.1498%2023.7093H30.4205V24.5181H35.1498V23.7093ZM58.7072%2021.7246H53.294L53.1593%2021.8818C53.0539%2022.0048%2052.9711%2022.1017%2052.8887%2022.1981L52.8873%2022.1998L52.8859%2022.2014C52.8035%2022.2979%2052.7211%2022.3943%2052.6161%2022.5169L52.5078%2022.6433V25.693L52.6161%2025.8194C52.7216%2025.9425%2052.8046%2026.0396%2052.8873%2026.1365L52.8877%2026.1369C52.9704%2026.2338%2053.0534%2026.3309%2053.1593%2026.4545L53.294%2026.6117H58.7989V25.7117H53.7079L53.5713%2025.5517L53.4075%2025.3602V22.9761L53.5713%2022.7845L53.7079%2022.6246H58.7072V21.7246ZM67.2254%2022.8677H63.6288L63.0125%2023.4842V26.0093L63.3319%2026.3288L63.4017%2026.3985L63.6288%2026.6257H67.2254L67.659%2026.192L67.8417%2026.0093V23.4842L67.2254%2022.8677ZM63.9123%2023.857L64.0015%2023.7677H66.8528L66.942%2023.857V25.6365L66.8528%2025.7257H64.0015L63.9123%2025.6365V23.857ZM68.8604%2023.0002H69.7601V25.5378C69.8143%2025.6014%2069.8624%2025.6573%2069.9159%2025.7187H72.7353C72.7889%2025.6559%2072.8387%2025.5983%2072.8957%2025.5331V23.0002H73.7954V25.8735L73.6825%2026.0011C73.523%2026.1815%2073.4406%2026.2777%2073.2868%2026.4594L73.1521%2026.6187H69.5097L69.3754%2026.4669C69.2104%2026.2803%2069.1235%2026.1789%2068.9668%2025.9937L68.8604%2025.8678V23.0002ZM60.6988%2021.8289V26.5005H61.5985V21.8289H60.6988ZM78.6036%2024.5813V23.7679H75.6552L75.566%2023.8571V25.6366L75.6552%2025.7258H78.5041L78.6039%2025.6275V24.5813H78.6036ZM79.5036%2023.6566V21.7939H78.6036V22.8679H75.2826L74.6663%2023.4843V26.0094L75.2826%2026.6258H78.8058V26.4814L78.9109%2026.5883L79.5039%2026.0044V23.6566H79.5036Z'%20fill='%23020617'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_6697_31479'%3e%3crect%20width='82'%20height='28.5217'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
基于开发机进行推理
以近期开源的音频基础模型 Higgs Audio v2 为例,演示如何使用英博云开发机实现将文本转换为音频,并且本地部署。开源 GitHub 链接:higgs-audio。
本示例为一个小规模的推理实例,旨在帮助用户快速上手并验证模型推理流程。运行时间约 1 小时,使用计算资源:单卡 NVIDIA RTX 4090 + 256G 共享存储,成本消耗约 5 元
该示例仅用于演示和验证,所需资源较少,部署和运行均较为便捷,适合新手快速体验完整的模型推理流程。
下载模型代码
从 GitHub 拉取项目
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
创建环境并安装依赖
conda create -n higgs python=3.12 -y
conda activate higgs
pip install -r requirements.txt
pip install -e .
零样本语音克隆
生成与提供的参考音频相似的音频。
python3 examples/generation.py \
--transcript "The sun rises in the east and sets in the west. This simple fact has been observed by humans for thousands of years." \
--ref_audio belinda \
--temperature 0.3 \
--out_path generation.wav
- 支持尝试其他声音。在
examples/voice_prompts中查看更多示例声音。 - 支持将自己的声音添加到文件夹中。
FastAPI 本地加载模型
在开发机创建一个 server.py 脚本
import subprocess
import uuid
import os
from fastapi import FastAPI, Form
from fastapi.responses import FileResponse
app = FastAPI(title="Higgs Audio API", description="语音合成接口,调用本地 generation.py 生成语音")
OUTPUT_DIR = "outputs"
os.makedirs(OUTPUT_DIR, exist_ok=True)
OUT_FILE = os.path.join(OUTPUT_DIR, "generation.wav") # 固定输出路径
@app.post("/generate", summary="生成语音")
async def generate_audio(
transcript: str = Form(..., description="要合成的文本"),
temperature: float = Form(0.3, description="生成温度,越低越稳定"),
):
"""
调用本地 generation.py 脚本,把输入文本合成为语音文件并返回。
"""
out_file = os.path.join(OUTPUT_DIR, f"{uuid.uuid4().hex}.wav")
# 调用你现有的 generation.py 脚本
cmd = [
"python3", "./examples/generation.py",
"--transcript", transcript,
"--temperature", str(temperature),
"--model_path", "/data/higgs-audio/higgs-audio-v2-generation-3B-base",
"--device_id", "0",
"--ref_audio_in_system_message",
"--out_path", OUT_FILE
]
result = subprocess.run(cmd, capture_output=True, text=True)
# 打印日志方便调试
print("stdout:", result.stdout)
print("stderr:", result.stderr)
# 如果生成失败,返回报错信息
if result.returncode != 0 or not os.path.exists(OUT_FILE):
return {"error": "生成失败", "stderr": result.stderr}
# 返回音频文件
return FileResponse(OUT_FILE, media_type="audio/wav", filename="generation.wav")
启动服务
uvicorn server:app --host 0.0.0.0 --port 8000
配置 SSH 隧道转发
在本机 CMD 或 PowerShell 中执行以下命令:
ssh -p 3xxxx -L 9000:127.0.0.1:8000 root@ssh-cn-huabei1.ebcloud.com -N
输入密码并等待连接成功后,即可通过本地访问开发机服务。
注意:
- 更多关于配置 SSH 隧道转发的细节,可以参考这里。
fastapi 网页调用教程
打开浏览器访问 http://127.0.0.1:9000/docs
点击 default -> Try It out,输入文本和生成温度,等待几分钟,生成音频,可下载查看。 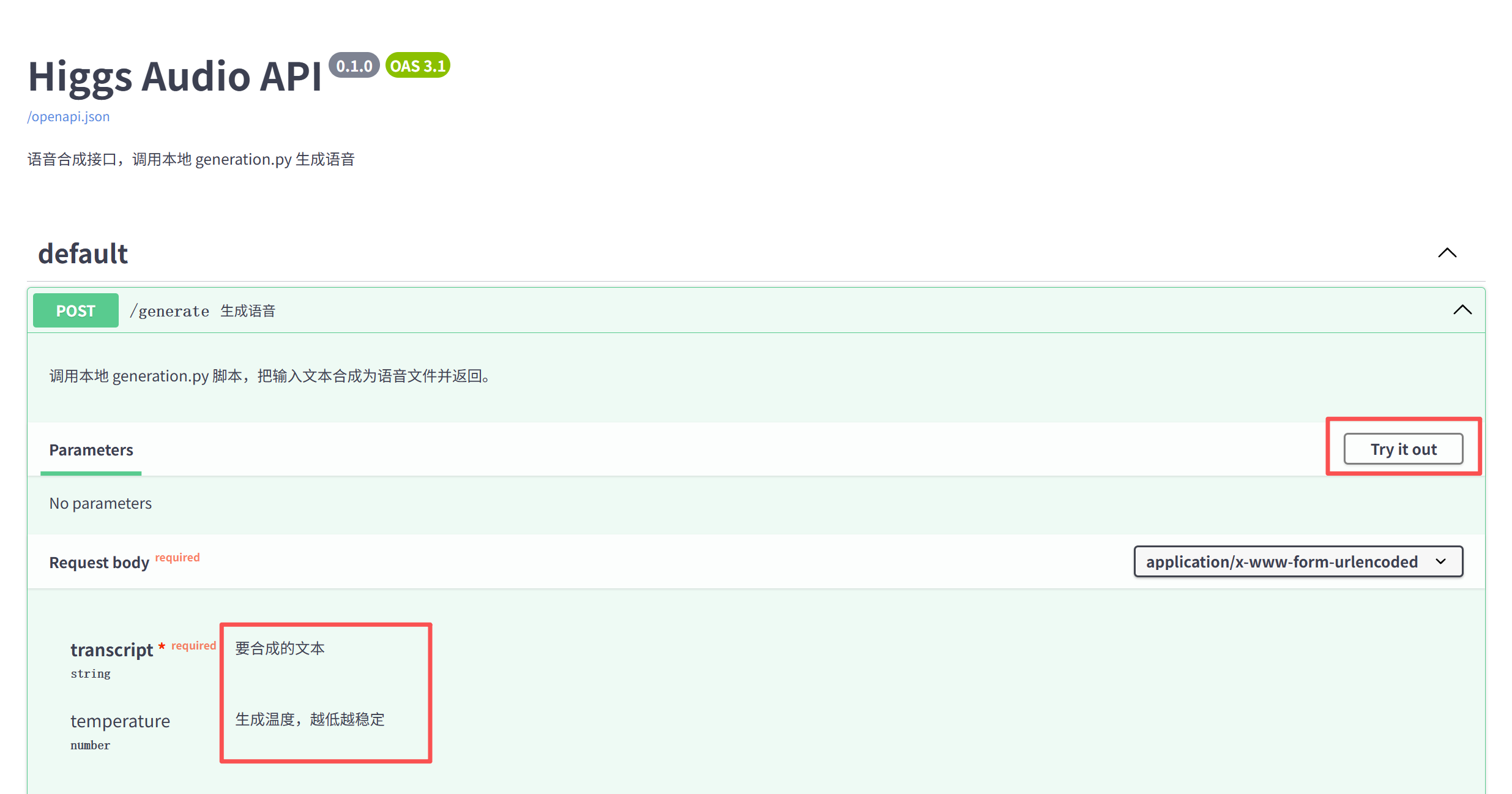
网页端生成音频的速度通常低于直接在开发机上使用 Python 命令执行,该网页仅提供简易测试功能,一些高级功能尚未实现,如需完整功能和最佳性能,请直接在开发机上运行 Python 脚本进行实验。